
Как правильно оценить эффективность маркетинговой акции и не запутаться в цифрах
5 мин

Большинство моих коллег привыкли использовать предиктивную аналитику только для получения прямого ответа «Да/Нет» на вопрос «Стоит ли запускать %название бизнеса%», однако это не совсем верный подход.
Комплекс предсказательной аналитики перед стартом нового бизнеса, без сомнения, незаменимая вещь. Но весь потенциал продукта лежит в поиске точек роста и призывает, в первую очередь, ответить на вопрос: «Что мне нужно улучшить, чтобы бизнес приносил больше денег?» и производные: «Как? Когда? Сколько?».
Стандартные модели предиктивной аналитики начинают иметь все больше расхождений с реальными показателями из-за непрерывного и активного роста аудитории рунета. По данным Всероссийского центра изучения общественного мнения, в первом квартале 2018 года интернетом пользовались 80% совершеннолетних россиян, причем 61% делали это ежедневно.
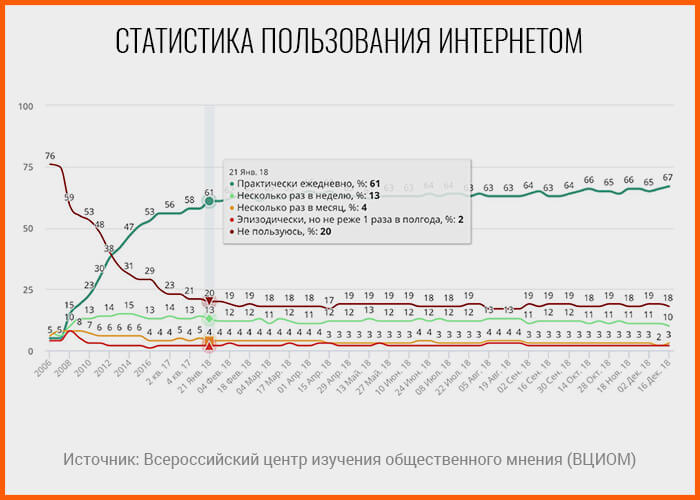
Примером апологетики можно считать следующие данные:
По уровню доступа к информационным технологиям Россия находится на 48 месте из 159 стран;
Динамика роста российской интернет-аудитории с 2000 по 2010 годы составила 1826% (источник: РИА Новости);
По состоянию на декабрь 2018 года в России зарегистрировано более 40М уникальных IPv4-адресов;
При использовании в работе процессов анализа и прогнозирования 4-летней давности мы получаем расхождение уже в 20% против 5–7% в начале исследования. Данные погрешности также включают в себя постоянно обновляющиеся алгоритмы работы поисковых систем, особенно те, которые оценивают поведенческие факторы.
В период с 2009 по 2015 год подход к прогнозам и продвижению в двух основных поисковых системах Яндекс и Google отличался лишь незначительно. Но после обновления алгоритма Яндекса «Минусинск», который в большей степени затронул группы ссылочных факторов, подход к прогнозам сильно изменился.
Теперь все большее число факторов ранжирования зависит от методов обучения нейронных сетей поисковых систем. И так как в свободном доступе информация о технологии работы алгоритмов отсутствует, точно просчитать отдачу невозможно.
С 2015 по 2018 год было введено 6 широких апдейтов работы поисковых систем, базирующихся исключительно на машинном обучении, в которых больше всего внимания уделено группам поведенческих факторов и текстовой оптимизации. Данные новшества — серьезная преграда к проведению «чистых экспериментов» над поисковой выдачей, так как все стандартные модели изначально базировались на отсутствии «шумных» данных.
Кроме того, в поисковой системе появились так называемые «Многорукие Бандиты» – специальный алгоритм, который рандомизирует выдачу на малых процентных выборках аудитории 4–10%, из-за чего предугадать соответствие позиция – трафик – конверсии становится все труднее.
Основные задачи любой маркетинговой аналитики – поиск точек роста для бизнеса, а именно:
поиск лучших запросов для увеличения трафика;
поиск лучших продуктов для увеличения выручки;
анализ аудитории для повышения конверсии;
оптимизация расходов для роста прибыли;
скоринг для снижения рисков;
Изменения в алгоритмической выдаче носят позитивный характер для конечного пользователя. Потому что проекты, которые строили свою работу на создании и доставке полезного контента, давали полный широкий ответ, получили значительные преимущества. С введением последнего алгоритма «Андромеда» в ноябре 2018 года сместилась важность основных кликовых факторов — смещение произошло в сторону доступности конечного контента: сейчас пользователь может получить ответ прямо на странице поисковой выдачи (SERP), либо моментально загрузить документ с помощью Турбо-Страниц.
Перед профильными специалистами стоит задача разработать методологию прогнозной аналитики таким образом, чтобы можно было учитывать неравномерный рост количества пользователей, рандомизацию ответов в результатах поиска и неравномерный рост собственных сервисов поисковых систем.
При системном подходе к решению задачи, мы выделяем 3 промежуточных этапа, достижение которых полностью покрывает требования:
Сбор семантического ядра.
Исследование, разработка и внедрение методологии прогноза позиций.
Исследование, разработка и внедрение прогноза органического трафика.
Начиная с 2016 года поисковая система, благодаря алгоритму «Палех», учитывает соответствие поисковому запросу семантического вектора с целью определения близости данного вектора к заголовкам проиндексированных документов в сети. Благодаря этому, мы можем добавлять в семантику не только маркерные запросы, но и низкочастотные и микрочастотные запросы.
Дальнейшее развитие и преобразование «Палеха» в «Королев» дает возможность добавлять в семантику не только векторные ключи, но и позволяет учитывать интент запроса, что ранее было невозможно. В результате, объем конечного семантического ядра вырос с 2,5 тысяч слов на средний информационный проект до 12–15 тысяч. Кроме этого, благодаря возможности кластеризации оптимизация ресурса с «запрос-документ» перешла в «кластер-документ».
Собрать абсолютно верное ядро на текущий момент не представляется возможным. Оптимизатор просто не в состоянии предугадать и покрыть 100% пользовательских интентов. Но как показывает практика, используя все последние методы сбора семантики, мы закрывает если не всю, только большую часть.
После сбора полного ядра для построения модели семантических графов необходимо получить 3 типа частотностей запросов: базовый, точный, уточненный. Важно обратить внимание на расширенные характеристики каждого запроса и вести расчет отдельно по каждой группе.
1. По геозависимости:
2. По частотности:
3. По уровню коммерции:
4. По коммерческому спросу:
4. По тематическому классификатору.
5. По посадочным страницам:
5. По типу:
При построении прогноза стоит вводить линию тренда не только по модели временного ряда, но и по прохождению кворума. Этот этап является критически важным – пропустить его равно отодвинуть сроки реализации проекта на 4–6 месяцев.
Для попадания в результаты выдачи, документ должен содержать в себе и/или текстах, входящих на него ссылок все или заданную минимальную долю веса слов из запроса. Доля высчитывается как функция от длины запроса (в словах) и весов слов, входящих в него по формуле:

Также, при построении модели следует учитывать запросный индекс: совокупность поисковых запросов, которые ведут на документ. В нашем случае, будет верным аналитика топ-50 SERPа по группам маркерных запросов, с последующим включением данных в нашу модель.
При построении запросного индекса учитывается весь тематический корпус документов, который содержит в себе десятки (если уже не сотни) тысяч документов. Исходя из патентов Google, мы знаем, что поисковые машины используют иерархическую классификацию коллекций документов, что дает нам полное право отнести все веса важных для нас групп факторов к скалярным и, как следствие, настроить простой скоринг.
Однако, с последними нововведениями Яндекс, в частности, алгоритма «Андромеда», существует мнение о том, что кроме обычных коллекций в поиске появятся еще «эталонные выборки», т.е. перекос факторов будет все больше идти в сторону сильного социального комьюнити и сопутствующих факторов: брендовый трафик, тайп-ин и т.д. Это означает, что все больше данных для специалиста станут неподконтрольными, а качество прогноза упадет на еще несколько процентов.
В связи с этим, была выведена формула дисперсии позиций по SERPу с соответствующими коэффициентами T1, T2, T3 и T3.
Итоговые значения для группировок запросов можно свести к следующим параметрам (Таблица 1):
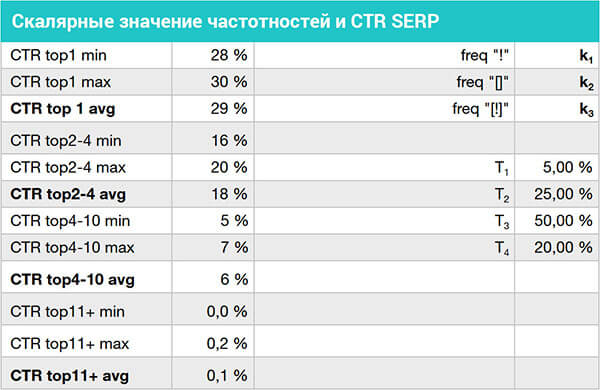
Таблица 1: Средний CTR топ-10 Яндекс, типы частотностей и дисперсия распределения позиций по SERP
Основополагающая веха построения прогнозной аналитики поисковой оптимизации лежит в точности определения CTR в SERPе на короткой и средней дистанциях. Методы, описанные в данном материале, являются базовыми:
Получение CTR через сервисы Яндекс.Вебмастер.
Получение CTR через сопоставление данных аналитической системы и съемщика позиций по заданным критериям (необходимо сравнение с ближайшими (3–5 мест) конкурентами в SERPе).
Поиск открытых счетчиков аналитических систем конкурентов и сопоставление с их позициями.
Покупка данных.
При получении исходных данных мы просто перемножаем данные значения на коэффициенты, полученные по частотностям k и высчитываем медианное значение.
Итоговая формула выглядит так:
.png?width=812&name=CodeCogsEqn%20(1).png)
Где:
V — совокупное прогнозируемое количество трафика из органического поиска
k — совокупная частотность всего ядра запросов
С — среднее значение CTR заданной позиции в SERPе
T — коэффициент дисперсии позиций
Методология аналитики на основе семантических графов дала наиболее точные результаты на дистанции в 18 месяцев и среднюю погрешность по 8 проектам в районе 12 процентов (от 5 до 19%), что является более чем приемлемым результатом.
Помощь профессионалов

Увеличьте продажи с помощью Inbound-маркетинга
Inbound-маркетинг естественным образом, не продавая, помогает клиентам выбирать ваши продукты и ваш бренд.
Подробнее


Комментарии